Welcome to the second edition of the FRCSyn, the Face Recognition Challenge in the Era of Synthetic Data organized at CVPR 2024.

To promote and advance the use of synthetic data for face recognition, we organize the second edition of the Face Recognition Challenge in the Era of Synthetic Data (FRCSyn). This challenge intends to explore the application of synthetic data to the field of face recognition in order to find solutions to the current limitations in the technology, for example, in terms of privacy concerns associated with real data, bias in demographic groups (e.g., ethnicity and gender), and lack of performance in challenging conditions such as large age gaps between enrolment and testing, pose variations, occlusions, etc.
In this second edition, we propose new sub-tasks that allow participants to train face recognition systems using novel face synthesis methods, with/without restrictions.
This challenge intends to provide an in-depth analysis of the following research questions:
- What are the limits of face recognition technology trained only with synthetic data?
- Can the use of synthetic data be beneficial to reduce the current limitations in face recognition technology?
FRCSyn challenge will analyze improvements achieved using synthetic data and the state-of-the-art face recognition technology in realistic scenarios, providing valuable contributions to advance the field.
FRCSyn Challenge: Summary Paper
📝 The summary paper of the 2nd FRCSyn Challenge is available here.
News
- 1 Apr 2024 FRCSyn Challenge ends
- 16 Jan 2024 FRCSyn Challenge starts
- 15 Jan 2024 Website is live!
Schedule, 18th June 2024, Morning
| Time (Seattle) | Duration | Activity |
|---|---|---|
| 8:10 – 8:20 | 10 min | Introduction to 2nd FRCSyn Workshop |
| 8:20 – 9:00 | 40 min | Keynote 1: Shalini De Mello |
| 9:00 – 9:15 | 15 min | 2nd FRCSyn Challenge |
| 9:15 – 10:15 | 60 min | Top-ranked Teams (11) + Q&A |
| 10:15 – 10:30 | 15 min | Break |
| 10:30 – 11:10 | 40 min | Keynote 2: Fernando De la Torre |
| 11:10 – 11:50 | 40 min | Keynote 3: Naser Damer |
| 11:50 – 12:00 | 10 min | Closing Notes |
Keynote Speakers
|
Title: In the Era of Synthetic Avatars: From Training to Verification Abstract: We are witnessing a rise in generative AI technologies that make the creation of digital avatars automated and accessible to anyone. While it is clear that such AI technologies will benefit numerous digital human applications, from video conferencing to AR/VR, their successful adoption hinges on their ability to generalize to real-world data. In this talk, I discuss our recent efforts to utilize synthetic data to create AI models for synthesizing photorealistic humans. First, I will share our recent efforts on learning to generate photorealistic 3D faces from a collection of in-the-wild 2D images at their native image resolution. Furthermore, I will show how such photorealistic 3D synthetic data can be used to train another AI model for downstream applications, such as a single-view reconstruction of photorealistic faces. Lastly, I will address the emerging challenge of verifying the authenticity of synthetic avatars in a world where their legitimate use becomes ubiquitous. Short bio: Shalini De Mello is a Director of Research, New Experiences and a Distinguished Research Scientist at NVIDIA, where she leads the AI-Mediated Reality and Interaction Research Group. Previously, she was a researcher in the Learning and Perception Research Group at NVIDIA, from 2013 to 2023. Her research interests are in AI, computer vision and digital humans. Her research focuses on using AI to re-imagine interactions between humans, and between humans and machines. She has co-authored scores of peer-reviewed publications and patents. Her inventions have contributed to several NVIDIA AI products, including DriveIX, Maxine and TAO Toolkit. She received her Doctoral and Master’s degrees in Electrical and Computer Engineering from the University of Texas at Austin. |
|
|
Title: Zero-shot/few-shot learning for model diagnosis and debiasing generative models, and its applications to face analysis Abstract: In practice, metric analysis on a specific train and test dataset does not guarantee reliable or fair ML models. This is partially due to the fact that obtaining a balanced (i.e., uniformly sampled over all the important attributes), diverse, and perfectly labeled test dataset is typically expensive, time-consuming, and error-prone. To address this issue, first, I will describe zero-shot model diagnosis, a technique to assess deep learning model failures in visual data. In particular, the method will evaluate the sensitivity of deep learning models to arbitrary visual attributes without the need of a test set. In the second part of the talk, I will describe IT-GEN, an inclusive text-to-image generative model that generates images based on human-written prompts and ensures the resulting images are uniformly distributed across attributes of interest. Applications related to face recognition will be described. Short bio: Fernando De la Torre received his B.Sc. degree in Telecommunications, as well as his M.Sc. and Ph. D degrees in Electronic Engineering from La Salle School of Engineering at Ramon Llull University, Barcelona, Spain in 1994, 1996, and 2002, respectively. He has been a research faculty member in the Robotics Institute at Carnegie Mellon University since 2005. In 2014 he founded FacioMetrics LLC to license technology for facial image analysis (acquired by Facebook in 2016). His research interests are in the fields of Computer Vision and Machine Learning. In particular, applications to human health, augmented reality, virtual reality, and methods that focus on the data (not the model). He is directing the Human Sensing Laboratory (HSL). |
|
|
Title: Introducing Variation in Synthetic Face Recognition Training Data Abstract: Motivated by the technical, legal, and ethical need for more diverse, representative, and privacy-aware data to build a face recognition system, huge efforts are rightfully spent on developing synthetic-based face recognition solutions. This workshop, and its associated competition are one of the main efforts in this direction. One of the main requirements in face recognition training data, being authentic or synthetic, is to contain large, realistic, and diverse variations. These variations typically mimic possible variations that the face recognition model will encounter in operation. Such facial variations can include concrete and easily understandable aspects such as pose, age, demographic groups, or facial hair, among others. However, realistic facial variations are more complex and include much more complicated correlations. This talk will discuss training face recognition models based on synthetic data with a focus on the introduction of such facial variation in the synthetic data in the generator training and synthesis processes. Short bio:Dr. Naser Damer is a senior researcher at the competence center Smart Living & Biometric Technologies, Fraunhofer IGD. He received his master of science degree in electrical engineering from the Technische Universität Kaiserslautern (2010) and his PhD in computer science from the Technischen Universität Darmstadt (2018). He is a researcher at Fraunhofer IGD since 2011 performing applied research, scientific consulting, and system evaluation. His main research interests lie in the fields of biometrics, machine learning and information fusion. He published more than 50 scientific papers in these fields. Dr. Damer is a Principal Investigator at the National Research Center for Applied Cybersecurity CRISP in Darmstadt, Germany. He serves as a reviewer for a number of journals and conferences and as an associate editor for the Visual Computer journal. He represents the German Institute for Standardization (DIN) in ISO/IEC SC37 biometrics standardization committee. |



Tasks
FRCSyn focuses on the two following challenges in current face recognition technology:
- Task 1: synthetic data for demographic bias mitigation.
- Task 2: synthetic data for overall performance improvement (e.g., age, pose, expression, occlusion, demographic groups, etc.).
Within each task, we propose in the 2nd Edition of FRCSyn three sub-tasks, considering alternative approaches for training face recognition technology:
- Exclusively with synthetic data constrained to maximum 500,000 face images (e.g., 10,000 identities and 50 images per identity). Synthetic face images can be generated using any state-of-the-art methods, no restrictions. We provide some suggestions in the following section.
- Exclusively with synthetic data with no limit on the number of face images. Synthetic face images can be generated using any state-of-the-art methods, no restrictions. We provide some suggestions in the following section.
- Combining real and synthetic data constrained to: 1) for real data, only the proposed CASIA-WebFace dataset (around 500,000 real face images), provided to the participants after registration. 2) for synthetic data maximum 500,000 synthetic face images (e.g., 10,000 identities and 50 images per identity). Synthetic face images can be generated using any state-of-the-art methods, no restrictions. We provide some suggestions in the following section. Participants are free to combine the allowed real and synthetic data as they prefer.
Synthetic Datasets
One of the novelties in this second edition of the FRCSyn Challenge is that there are no fixed datasets for the training with synthetic data. We allow participants to use any generative framework to create the synthetic datasets for the three sub-tasks of the challenge (considering the corresponding limitations of each sub-task in terms of the number of face images used for training).
We list some state-of-the-art generative frameworks that could be used as reference:
DCFace: a novel framework entirely based on Diffusion models, composed of i) a sampling stage for the generation of synthetic identities XID, and ii) a mixing stage for the generation of images XID,sty with the same identities XID from the sampling stage and the style selected from a “style bank” of images Xsty.
Reference M. Kim, F. Liu, A. Jain and X. Liu, “DCFace: Synthetic Face Generation with Dual Condition Diffusion Model”, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023.
GANDiffFace: a novel framework based on GANs and Diffusion models that provides fully-synthetic face recognition datasets with the desired properties of human face realism, controllable demographic distributions, and realistic intra-class variations. Best Paper Award at AMFG @ ICCV 2023.
Reference P. Melzi, C. Rathgeb, R. Tolosana, R. Vera-Rodriguez, D. Lawatsch, F. Domin, M. Schaubert, “GANDiffFace: Controllable Generation of Synthetic Datasets for Face Recognition with Realistic Variations”, in Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, 2023.
DigiFace-1M: a large-scale synthetic dataset obtained by rendering digital faces with a computer graphics pipeline. Each identity of DigiFace-1M is defined as the unique combination of facial geometry, texture, eye color, and hairstyle, while other parameters (i.e. pose, expression, environment, and camera distance) are varied to render multiple images.
Reference G. Bae, M. de La Gorce, T. Baltrusaitis, C. Hewitt, D. Chen, J. Valentin, R. Cipolla, and J. Shen, “DigiFace-1M: 1 Million Digital Face Images for Face Recognition”, in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2023.
IDiff-Face: a novel approach based on conditional latent diffusion models for synthetic identity generation with realistic identity variations for face recognition training.
Reference F. Boutros, J. Henry Grebe, A. Kuijper, N. Damer, “IDiff-Face: Synthetic-based Face Recognition through Fizzy Identity-Conditioned Diffusion Model”, in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023
ID3PM: a novel approach that leverages the stochastic nature of the denoising diffusion process to produce high-quality, identity-preserving face images with various backgrounds, lighting, poses, and expressions.
Reference M. Kansy, A. Raël, G. Mignone, J. Naruniec, C. Schroers, M. Gross, R. M. Weber, “Controllable Inversion of Black-Box Face Recognition Models via Diffusion”, in Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, 2023.
SFace: a privacy-friendly synthetically generated face dataset is proposed, based on the training of StyleGAN2-ADA with real datasets, and the setting of identity labels as class labels to create synthetic data
Reference F. Boutros, M. Huber, P. Siebke, T. Rieber, and N. Damer, “SFace: Privacy-friendly and accurate face recognition using synthetic data”, in Proceedings of the IEEE International Joint Conference on Biometrics, 2022.
SYNFace: a novel framework that proposes the use of DiscoFaceGAN for the synthesis of face images, a disentangled learning scheme that enables precise control of targeted face properties such as identity, pose, expression, and illumination
Reference H. Qiu, B. Yu, D. Gong, Z. Li, W. Liu, D. Tao, “SYNFace: Face Recognition With Synthetic Data”, in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021.
Registration
The platform used in the 2nd edition of FRCSyn Challenge is CodaLab. Participants need to register to take part in the challenge. Rules and important information are in the CodaLab. Please, follow the instructions:
- Fill up this form including your information. We allow a maximum of 6 members per team.
- Sign up in CodaLab using the same email introduced in step 1).
- Join in CodaLab the CVPR 2024 FRCSyn Challenge. Just click on the “Participate” tab for the registration.
- We will give you access once we check everything is correct.
- You will receive an email with all the instructions to kickstart FRCSyn, including links to download datasets, experimental protocol, and an example of a submission file.
Paper
The best teams of each sub-task will be invited to contribute as co-authors in the summary paper of the 2nd edition of FRCSyn challenge, similar to what we did in the first edition at WACV 2024 (Reference). This paper will be published in the proceedings of the CVPR 2024 conference. In addition, top performers will be invited to present their methods at the workshop.
Important Dates
- 16 January 2024: 2nd edition of the FRCSyn Challenge starts
- 1 April 2024: 2nd edition of the FRCSyn Challenge ends
- 3 April 2024: Announcement of winning teams
- 14 April 2024: Paper submission with results of the challenge
- 18 June 2024: 2nd edition of FRCSyn Workshop at CVPR 2024
FRCSyn at CVPR 2024: Results
| Sub-Task 1.1 (Bias Mitigation): Synthetic Data (Constrained) | |||||||
|---|---|---|---|---|---|---|---|
| Pos. | Team | TO [%] | AVG [%] | SD [%] | FNMR@FMR=1% | AUC [%] | GAP [%] |
| 1 | ID R&D | 96.73 | 97.55 | 0.82 | 3.17 | 99.57 | -5.31 |
| 2 | ADMIS | 94.30 | 95.10 | 0.80 | 11.38 | 98.96 | 1.47 |
| 3 | SRCN_AIVL | 94.06 | 95.12 | 1.07 | 10.72 | 98.83 | -0.54 |
| 4 | OPDAI | 93.75 | 94.92 | 1.17 | 11.85 | 99.51 | 1.02 |
| 5 | CTAI | 93.21 | 94.74 | 1.53 | 14.38 | 98.33 | -0.63 |
| 6 | K-IBS-DS | 92.91 | 94.11 | 1.20 | 15.03 | 98.47 | 1.58 |
| Sub-Task 1.2 (Bias Mitigation): Synthetic Data (Unconstrained) | |||||||
|---|---|---|---|---|---|---|---|
| Pos. | Team | TO [%] | AVG [%] | SD [%] | FNMR@FMR=1% | AUC [%] | GAP [%] |
| 1 | ID R&D | 96.73 | 97.55 | 0.82 | 3.17 | 99.57 | -5.31 |
| 2 | ADMIS | 95.72 | 96.50 | 0.78 | 6.33 | 99.51 | -0.56 |
| 3 | OPDAI | 94.12 | 95.22 | 1.11 | 10.78 | 98.92 | 0.71 |
| 4 | INESC-IGD | 94.05 | 95.22 | 1.17 | 11.03 | 98.70 | 1.04 |
| 5 | K-IBS-DS | 93.72 | 94.88 | 1.16 | 12.75 | 99.66 | 0.77 |
| 6 | CTAI | 93.21 | 94.74 | 1.53 | 14.38 | 98.33 | -0.63 |
| Sub-Task 1.3 (Bias Mitigation): Synthetic + Real Data (Constrained) | |||||||
|---|---|---|---|---|---|---|---|
| Pos. | Team | TO [%] | AVG [%] | SD [%] | FNMR@FMR=1% | AUC [%] | GAP [%] |
| 1 | ADMIS | 96.50 | 97.25 | 0.75 | 3.90 | 99.72 | -1.33 |
| 2 | K-IBS-DS | 96.17 | 96.92 | 0.75 | 5.88 | 99.54 | -1.37 |
| 3 | UNICA-IGD-LSI | 96.00 | 96.70 | 0.70 | 5.90 | 99.49 | -5.33 |
| 4 | OPDAI | 95.96 | 96.80 | 0.84 | 4.90 | 99.54 | -0.03 |
| 5 | INESC-IGD | 95.65 | 96.33 | 0.67 | 6.15 | 99.18 | -0.12 |
| 6 | CBSR-Samsung | 95.57 | 96.54 | 0.97 | 5.00 | 99.41 | -24.43 |
| Sub-Task 2.1 (Bias Mitigation): Synthetic Data (Constrained) | |||||
|---|---|---|---|---|---|
| Pos. | Team | AVG [%] | FNMR@FMR=1% | AUC [%] | GAP [%] |
| 1 | OPDAI | 91.93 | 17.63 | 97.30 | 3.09 |
| 2 | ID R&D | 91.86 | 10.36 | 97.48 | 2.99 |
| 3 | ADMIS | 91.19 | 20.41 | 97.04 | 2.78 |
| 4 | K-IBS-DS | 91.05 | 24.87 | 96.09 | 2.60 |
| 5 | CTAI | 90.59 | 21.88 | 96.40 | -1.94 |
| 6 | BOVIFOCR-UFPR | 89.97 | 24.04 | 96.70 | 3.71 |
| Sub-Task 2.2 (Bias Mitigation): Synthetic Data (Unconstrained) | |||||
|---|---|---|---|---|---|
| Pos. | Team | AVG [%] | FNMR@FMR=1% | AUC [%] | GAP [%] |
| 1 | Idiap-SynthDistill | 93.50 | 9.17 | 97.17 | -0.05 |
| 2 | ADMIS | 92.92 | 14.45 | 97.76 | 0.21 |
| 3 | OPDAI | 92.04 | 16.48 | 97.41 | 3.00 |
| 4 | ID R&D | 91.86 | 10.36 | 97.48 | 2.99 |
| 5 | K-IBS-DS | 91.61 | 22.48 | 96.54 | 1.96 |
| 6 | CTAI | 90.59 | 21.88 | 96.40 | -1.94 |
| Sub-Task 2.3 (Bias Mitigation): Synthetic + Real Data (Constrained) | |||||
|---|---|---|---|---|---|
| Pos. | Team | AVG [%] | FNMR@FMR=1% | AUC [%] | GAP [%] |
| 1 | K-IBS-DS | 95.42 | 9.49 | 98.14 | -2.15 |
| 2 | OPDAI | 95.23 | 7.54 | 98.70 | -0.52 |
| 3 | CTAI | 94.56 | 8.85 | 98.41 | -6.01 |
| 4 | CBSR-Samsung | 94.20 | 8.62 | 98.17 | -4.40 |
| 5 | ADMIS | 94.15 | 10.99 | 98.46 | -1.10 |
| 6 | ID R&D | 94.05 | 8.00 | 98.16 | 0.07 |
FRCSyn at CVPR 2024: Videos
The video presentations of the Top Teams are available here.
|
ADMIS 
|
OPDAI 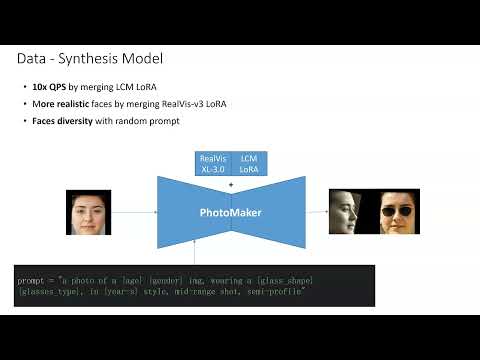
|
ID R&D 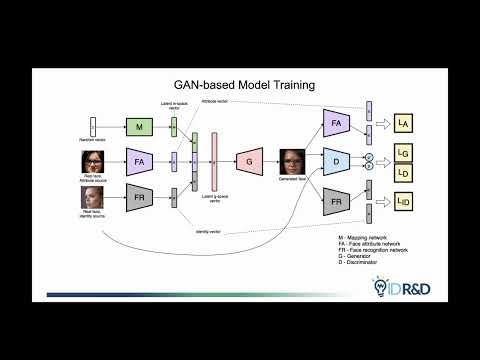
|
K-IBS-DS 
|
|
CTAI 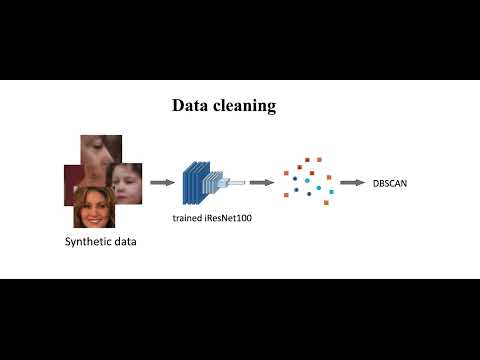
|
Idiap-SynthDistill 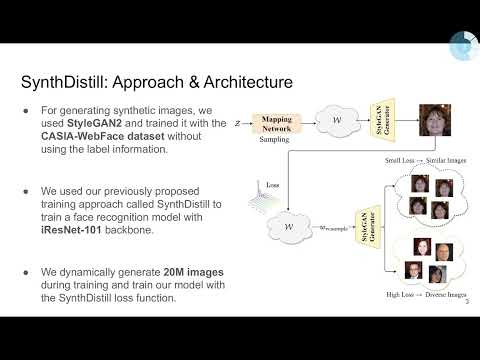
|
INESC-IGD 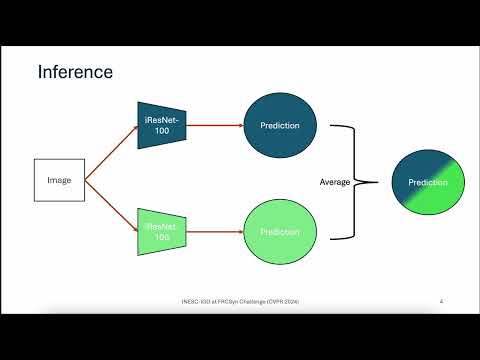
|
UNICA-IGD-LSI 
|
|
SRCN-AIVL 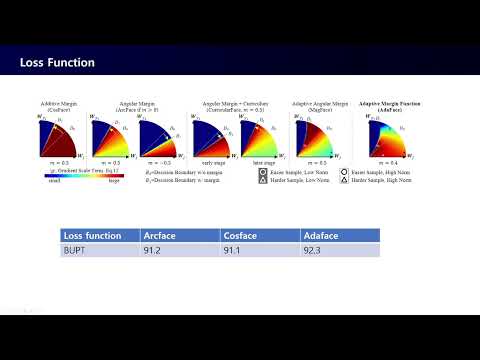
|
BOVIFOCR-UFPR 
|
Organizers










Fundings
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|






